
Аннотация: Понимание принципов консенсуса в сообществах и нахождение путей для нахождения решений оптимальных сообщества в целом становится критически важным по мере увеличения скоростей и масштабов взаимодействия в современных распределенных системах. Такими системами могут являться как социально-информационные компьютерные сети, объединяющие массы людей, так и много-агентные вычислительные платформы, в том-числе — одно-ранговые, действующие на основе распределенных реестров. Наконец, в настоящее время становится возможным появление гибридных экосистем, которые включают и человека, и компьютерные системы с использованием искусственного интеллекта.
Мы предлагаем новую форму консенсуса для подобных систем, основанную на репутации участников, вычисляемой согласно принципу «текучей демократии». Полагаем, что такая система будет иметь большей сопротивляемостью к социальной инженерии и манипуляцией репутацией, чем у действующих систем. В этой статье мы обсуждаем основные принципы и варианты реализации такой системы, а также представляем предварительные практические результаты. (по материалам статьи: https://arxiv.org/pdf/1811.08149.pdf )
Введение и предпосылки
Начиная с появления децентрализованных и распределенных компьютерных систем без централизованного управления, стало понятно, что надежность определения репутации участников представляет собой серьезную проблему, и эта проблема была объектом всестороннего изучения. Надежное решение по определению репутации узла вычислительной сети оказывается критичным для одно-ранговых систем, в которых каждый узел может взаимодействовать с любым другим узлом в сети. Стандартные теоретические основы для нахождения решения связаны с так называемой «задачей византийских генералов», где переменное число участников с переменными уровнями доверия независимо голосует для достижения консенсуса по решению, которое вносится в публичный реестр, чтобы все сообщество узнало об этом решении и чтобы это решение было для него благоприятным. Поскольку уровень доверия каждого узла системы заранее неизвестен, необходимо снизить риск воздействия на принятие решения со стороны узлов-«предателей», которые пытаются повлиять на консенсус в пользу враждебной части сообщества, одержав верх над остальными членами. В существующих распределенных вычислительных системах, основанных на технологии блокчейн, применяются различные алгоритмы достижения консенсуса, использующие различные формы взвешенного голосования, каждая из которых предлагает определенную эвристику, какое качество узла в компьютерной сети можно использовать, чтобы догадаться о его ожидаемом уровне доверия.
Для построения любых систем коллективного интеллекта или просто коллективного принятия решения при большом числе участников и отсутствию жесткой иерархической управляющей структуры («вертикали власти»), необходимы как достаточная автономность в выработке собственных вариантов решений каждым и участников, так и возможность быстрого и надежного определения общественного консенсуса в пределах всей системы. Для предотвращения злоупотреблений и манипуляций в подобной распределенной много-агентной сети необходима высококачественная репутационная система. Например, в создаваемой системе общего искусственного интеллекта (ОИИ) SingularityNET, обеспечение высоко-надежного репутации требует искусственного интеллекта (ИИ) само по себе, что ведет к взаимной рекурсии между ОИИ и оценкой репутации в распределенных системах ИИ. Таким образом, умение построить надежную систему исчисления репутации участников является критически важным для решения проблем ОИИ, и любая парадигма ОИИ должна тем или иным образом решать «проблему доверия» в отношениях между элементами много-агентной системы. Мы полагаем, что решение состоит из двух частей — А) относительно простой базовый алгоритм для определения репутации как «уровня доверия» между участниками в простых общих случаях и Б) система, которая занимается верификацией оценок на основе базового алгоритма на основе методов ИИ, для более сложных случаев. Из описания очевидно, что подобное решение могло бы быть востребовано не только для обеспечений консенсуса в системах распределенного ИИ, но и в существующих человеческих онлайн-сообществах, а также в грядущих смешанных человеко-машинных экосистемах.
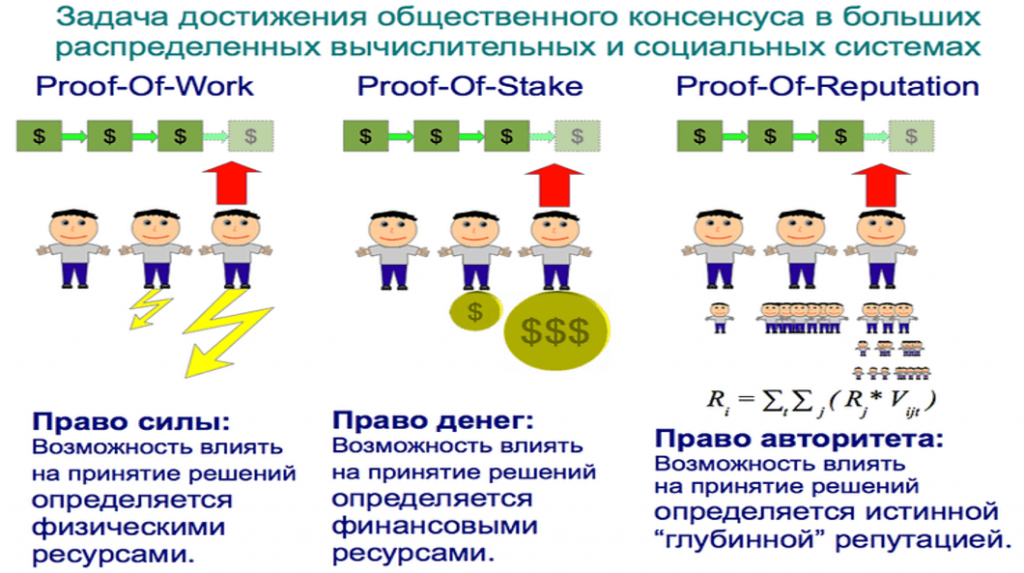
Большинство алгоритмов достижения консенсуса, обсуждавшихся в предыдущих работах и внедренных в существующие популярные распределенные вычислительные системы, такие как Ethereum и Bitcoin, подвержены взлому при известных обстоятельствах. Алгоритмом достижения консенсуса, называемым «доказательство права работой» или Proof-of-Work (POW), где участник системы голосует вычислительной мощностью, которой он владеет, может злоупотребить общество союзников, которые смогут в нужный момент сконцентрировать свыше 51% компьютерной мощности для достижения консенсуса в свою пользу. С исторической точки зрения на человеческое сообщество, данный алгоритм соответствует «праву силы», характерному для большинства древних сообществ и животных стай и стад. Еще один известный алгоритм достижения консенсуса, называемый «доказательство права финансовой ставкой» или «Proof-of-Stake» (POS), подразумевает голосование суммой финансовых средств, которыми владеет каждый участник. Это аналогично консенсусу в современных капиталистических обществах с «правом денег», где «богатый всегда богатеет». Такое решение приводит постепенно к глубокому разрыву в доходах, при котором со временем один участник или группа участников, сконцентрировавших достаточные средства, могут повлиять на достижение консенсуса исключительно в личных интересах, а не интересах всего сообщества. Усовершенствованная версия POS, называемая «делегирование права доказательства финансовой ставкой» или «Delegated-Proof-of-Stake» (DPOS), предполагается как решение последней проблемы явным делегированием права управлять «делегатам», назначенным участниками, владеющими большими долями, но это лишь приводит к ручному контролю над распределенной системой.
В настоящей работе мы предлагаем, по нашему мнению, более перспективную версию алгоритма достижения консенсуса, называемую «доказательство права репутацией» или «Proof-of-Reputation» (POR), которая может быть использована для построения «репутационного консенсуса» или консенсуса, основанного на репутации. В этом случае, возможности участника повлиять на достижение консенсуса могут определяться суммой репутации, социальным капиталом или «кармой», фактически заработанной участником в процессе взаимодействия с другими участниками в указанный период времени, принимая во внимание репутации самих этих участников. Описываемый ниже алгоритм реализует это на основе принципа «текучей демократии», где голоса одних участников неявно влияют на голоса других, перетекая в них, и называется алгоритмом «текучего ранжирования» или «liquid rank».
Побочным эффектом возможности вычислить надежный социальный консенсус в сообществе участников является способность выявить надежность каждого из участников, поддерживая наиболее эффективные и безопасные коммуникации между ними. Мы указывали на это в нашей предыдущей работе по разработке системы репутации для децентрализованного рынка услуг искусственного интеллекта, называемого SinglularityNET. Доказательство права репутацией предоставляет возможность измерить и отследить динамику развития репутации каждого участника общества. Это может быть применимо к любому обществу интеллектуальных агентов, реальных людей, взаимодействующих в социально-информационных сетях в среде Интернету, или даже гибридным человеко-машинным сообществам. Вычислительные решения построенные на основе описываемой технологии могут быть отнесены к классу «социальных вычислений» либо сама социальная среда рассматривается как средство распределенных вычислений репутаций каждого элемента этой среды.
Описанный в нашей последней статье алгоритм вычисления репутации «liquid rank» основан на методах вычисления количественных характеристик элементов графов в социальных сетях, реализованных в платформе персональной социальной аналитики Aigents и опубликованных в более ранних работах, адаптированных к проблеме расчета социальных репутаций для выстраивания лучшего алгоритма достижения консенсуса, основанного на репутации.
Варианты практической реализации
Положения и элементы алгоритма, предложенные выше, могут быть реализованы и использованы многими способами, в зависимости от решений, принятых относительно временных интервалов расчета репутации, а также вариантов обеспечения вычислений и хранения полученных данных, как будет рассмотрено ниже. В конце мы введем понятия «Репутационный консенсус» и «Доказательство права репутацией» и «Репутационный майнинг».
Определение временных интервалов
Работа репутационной системы будет зависеть от определения границ времени на основании охвата времени между циклами оценки репутации во временной промежуток от tn-1 до tn.
С одной стороны, возможен перерасчет «за весь период существования», когда учитываются все рейтинги между t0 и tn. В этом случае есть возможность учесть прошлые изменения в истории рейтинга при последующих перерасчетах. Однако это гораздо дороже и занимает больше времени. Также в этом случае нельзя достичь ухудшения репутации, как это было указано выше, и потребуется усложнение функций дифференциальной репутации, что приведет к появлению дополнительной, ограниченной во времени весовой функции, что будет придавать больший вес более недавним рейтингам.
С другой стороны, может быть «мгновенно-инкрементальный» перерасчет, где временные интервалы между t0 и tn соответствуют интервалам между последующими транзакциями, поэтому каждая транзакция влияет на глобальное изменение репутации. В этом случае отсутствует отсрочка в изменении репутации, но применение этого в распределенной среде может оказаться совсем не тривиальным. Вместе с тем это может оказаться благоприятным для распределенных систем, не основанных на технологии блокчейн.
Может быть реализован и «практически-инкрементальный» перерасчет, промежуточный между предыдущими двумя, где временные интервалы между t0 и tn – это года, кварталы, месяцы, недели, дни и т.д. Это более эффективный и быстрый способ, однако, изменение репутации может быть отсрочено, устареть ближе к концу интервала перерасчета.
И, наконец, есть нечто среднее между двумя последними способами, такое как «поблочно-инкрементальный» перерасчет, при котором используются блоки последних последующих транзакций для определения временного интервала. Внедрение этого способа в распределенные системы на основе блокчейн может оказаться вполне практичным.
Варианты обеспечения репутационных вычислений
С точки зрения поддержания существуют централизованный, децентрализованный и распределенный варианты. При «централизованном» варианте все репутации рассчитываются одной стороной или системой, которую назначило и которой доверяет сообщество, называемое Централизованное Репутационное Агентство.
При «децентрализованном» варианте все репутации рассчитываются многими сторонами или системами, которым эту функцию доверило сообщество, причем система из нескольких участвующих сторон может называться Децентрализованных Репутационным Агентством. В этом случае существуют еще два варианта. Первый — когда все агентства должны достичь консенсуса по текущему состоянию репутации, поэтому их можно назвать Децентрализованным Координированным Репутационным Агентством. Второй вариант – когда все они независимо поддерживают репутации, и в этом случае они будут являться Независимыми Децентрализованными Репутационными Агентствами.
В случае «распределенного» варианта все участники сообщества отвечают за расчет репутаций, например, как в блокчейне, где все участники сообщества могут отвечать за регистрацию и проверку транзакций. В этом случае также возможно либо достичь скоординированного консенсуса всех участников по состоянию репутаций («координированное агенство»), либо каждый будет иметь личную точку зрения на репутацию других («независимые агенства»).
Варианты хранения репутационных данных
При любом из вышеописанных вариантов возможно несколько подходов к хранению репутационных данных, а именно, они могут быть транзитными, с локальным постоянного хранением или глобальным постоянным хранением децентрализованным или распределенным способом.
В «транзитном» варианте все репутации всегда рассчитываются «на лету» вместе с доступными данными по удостоверениям и транзакциям. В случае «локального постоянного хранения» все вычисляемые репутации хранятся в локальном хранилище специально сформированного Репутационного Агентства или любого участника системы, без необходимости синхронизировать данные по статусу репутационной системы с другими участниками. Что касается «глобального постоянного хранения», то репутационные данные в этом случае поддерживаются децентрализованным или распределенным способом во всех Репутационных Агентствах или всеми участниками системы.
Децентрализованный репутационный консенсус
Если использовать разработки из нашей более ранней работы [6], небезынтересно рассмотреть, как различные Репутационные Агентства достигают децентрализованного консенсуса в отношении совместно используемых репутационных данных. Предлагается следующий алгоритм администрирования этого процесса.
Во время каждого цикла расчета репутации, каждое агенство отправляет другим свою версию статуса репутационной системы или информацию о состоянии репутационных данных, определяя репутацию для всех известных участников.
Для всех получателей в течение цикла каждое последующее полученное состояние после первого должно быть идентичным предыдущему.
Если очередное получаемое состояние не равно предыдущему, тогда набор последующих состояний отмечается как оспариваемый и в администрацию/службу текущего контроля отправляется предупреждение.
Как только получен требуемый системный минимум послледовательных идентичных состояний, состояние отмечается как достоверное, и больше состояния не принимаются.
Когда получен указанный системный максимум не идентичных состояний и имеется минимальное количество идентичных состояний, тогда состояние, которое поддерживается большинством отправлений, отмечается как достоверное, больше состояния не принимаются, и в администрацию/службу текущего контроля отправляется предупреждение, идентифицирующее отправителей не идентичного состояния.
Если в течение установленного системного периода, начиная с первого отправления, не происходит описанное в п. 4 и п. 5, консенсус считается нарушенным, никакие репутации не обновляются, а в администрацию/службу текущего контроля отправляется предупреждение, что нужно проверить всю репутационную систему.
В случае применения вышеуказанного процесса в распределенных системах, применяющих алгоритм достижения репутационного консенсуса для «доказательства права репутацией» или «Proof-of-Reputation» (POR) согласно нижеприведённому определению, голосование за принятое состояние репутации можно проводить с учетом репутации самих Агентств репутации с соответствующими изменениями в урегулировании спора, как это указано в п. 5 выше.
Доказательство права репутацией
В случае, когда сообщество, которое применяет расчеты репутации, проводит распределенные вычисления, необходимые для распределенного консенсуса в рамках системы на основе распределенного реестра, такой как блокчейн, вычисленная репутация может использоваться для целей достижения консенсуса в самой системе. Уровень репутации, заработанной конкретным узлом блокчейна, может влиять на его возможность повлиять на формирование блока таким же образом, как имеющаяся вычислительная мощность в случае Proof-of-Work или «сумма финансовой ставки» в случае Proof-of-Stake. Такого рода консенсус можно назвать «доказательство права репутацией» или «Proof-of-Reputation» (POR).
Майнинг репутации
Если репутации поддерживаются при распределенной реализации, когда их вычисляют посредством участия каждого участника сообщества, тогда это можно считать процессом «майнинга». Чтобы это произошло, состояния репутации, отправленные участниками, должны соответствовать протоколу децентрализованного репутационного консенсуса, описанного выше. В этом случае участник или несколько первых участников, которые первыми отправили соответствующие состояния репутации, признанные остальными участниками, имеют право получить компенсацию от сообщества, как это происходит в алгоритме консенсуса Proof-of-Work посредством решения криптографических задач, не имеющих никакой практической ценности.
Выводы и заключение
Данная статья является адаптированным сокращенным переводом на русский нашей более ранней работы, также доступна полная версия с небольшими дополнениями в части результатов, полученных за прошедшие полгода, а также нижеследующих выводов:
Представлена исчерпывающая модель вычисления репутаций в много-агентных системах, основанная на различного рода исторических данных, представляющих разнообразные способы взаимодействия между агентами.
Предложены различные способы построения репутационных систем, в зависимости от конкретных условий и требований.
Часть предложенных разработок доступна в виде вычислительной платформы персональной социальной аналитики Aigents на вебсайте https://aigents.com а также в открытом коде платформы Aigents: https://github.com/aigents/aigents-java.
Развитие репутационной системы и исследование её возможностей для распределенных экосистем и корпоративных систем ведется в рамках проекта по созданию экосистемы сервисов искусственного интеллекта с открытым кодом SingularityNET: https://github.com/singnet/reputation.
Продолжение работ идет как как в области имитационного моделирования, для изучения устойчивости репутационной системы репутации и репутационного консенсуса к различного рода манипуляциям и видам мошенничества направленным на умышленное искажение репутаций участников в пользу атакующих.
Ожидается дальнейшее развития распределенных репутационных систем и репутационных агенств, основанных на обсуждаемых принципах, а также их дальнейшее усовершенствование существующих.







